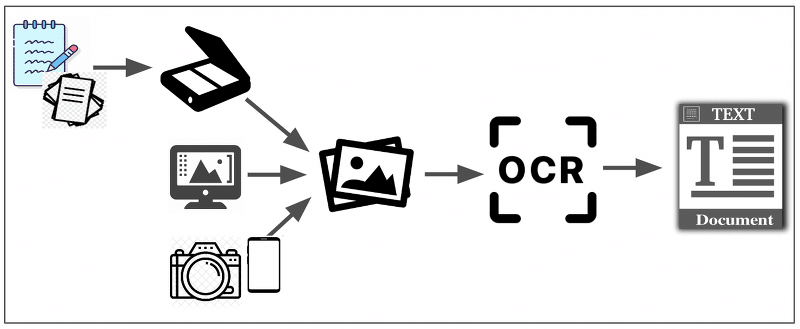
buyandelger 2024-03-26 OCR буюу Оптик тэмдэгт танилт нь хэвлэмэл болон гар бичмэл тэмдэгтийг компьютер уншиж чадахуйц текст болгож хөрвүүлэхийгхэлнэ. Ихэвчлэн тэмдэгт агуулсан зурган файлаас текст таниж засварлах, хайх боломжтой өгөгдөл болгон хувиргана. OCR (Оптик тэмдэгт танилт) хэрхэн ажилладаг вэ?Preprocessing: – convert to binary image – Noise Reduction – NormalizationFeature extraction: – Histogram Projection – Connected Component Analysis (CCA)Character Recognition: – Template matching – Pattern Recognition – Deep learning modelsPostprocessing: – Text Correction – Text SegmentationTraining and Optimization: – Supervised Learning -Train OCR models using labeled datasets of images and corresponding text Уламжлалт OCR алгоритмууд нь template matching, feature extractioan, and pattern recognition техникийг багтаасан.Орчин үеийн OCR нь ихэвчлэн Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), LSTM загварууд зэрэг deep learning архитектурт тулгуурладаг.Текстийг танихад ашигладаг хоёр үндсэн ocr алгоритм: TEMPLATE MATCHING: Оролтын дүрсийг тэмдэгтүүд эсвэл тэмдэгтүүдийг илэрхийлсэн урьдчилан тодорхойлсон загваруудтай харьцуулаад загвар бүрийн ижил төстэй байдлыг тооцоолж, хамгийн сайн тохирохыг сонгоно. FEATURE-BASED: Тэмдэгтүүдээс ирмэг, булан, бүтэц гэх мэт ялгаатай шинж чанаруудыг гаргаж авдаг. дараа нь эдгээр шинж чанаруудыг тэмдэгтүүдийг төлөөлөх, ангилахад ашигладаг. sift (scale-invariant feature transform), surf (speeded-up robust features) зэрэг аргууд байдаг. OCR төрөл : Based on Input Medium – Оролтын хэрэгсэлд үндэслэн – Print OCR: Processes printed text from documents, books, newspapers, etc. – Handwriting OCR (HWR): Recognizes handwritten text.Based on Application – Хэрэглээнд үндэслэн – Document OCR – mobile OCR – Receipt OCRBased on Output – Гаралт дээр үндэслэн – Simple – Текстийг таньж, энгийн текст хэлбэрээр гаргадаг. – Advanvced – Хүснэгт, маягт эсвэл тодорхой талбар гэх мэт бүтэцлэгдсэн өгөгдлийг баримтаас гаргаж авдаг.Based on Technology – Технологид суурилсан – Conventional OCR – Deep learning OCRBased on Language and Script – Хэл болон скрипт дээр үндэслэн: – Latin OCR – Англи, Франц, Испани гэх мэт – Non-Latin OCR – Араб, Хятад, Япон гэх мэтBased on Deployment – Cloud-based OCR – Интернэтээр нэвтрэх боломжтой алсын серверүүд – On-premise OCR – Байгууллагын дэд бүтцэд орон нутагт суурилуулсан OCR-ийг голдуу текст, тэмдэгт агуулсан зурган файлаас текст танихад ашигладаг ба дараах хэрэглээнүүдийг агуулдаг:Бүртгэлийн системд автоматаар бичиг баримтын файл эсвэл зургаас өгөгдөл оруулах, хадгалах, хайх боломжийг олгох.Авто машины дугаар танихПаспорт болон иргэний үнэмлэхээс мэдээлэл гаргаж авах Банкны картын дугаар танихЦахим бичиг баримт, номыг агуулгаар нь хайж болгохуйц болгох.Харааны бэрхшээлтэй иргэдэд бичиг баримт уншихад туслах гэх мэт өргөн хэрэглээтэй.