
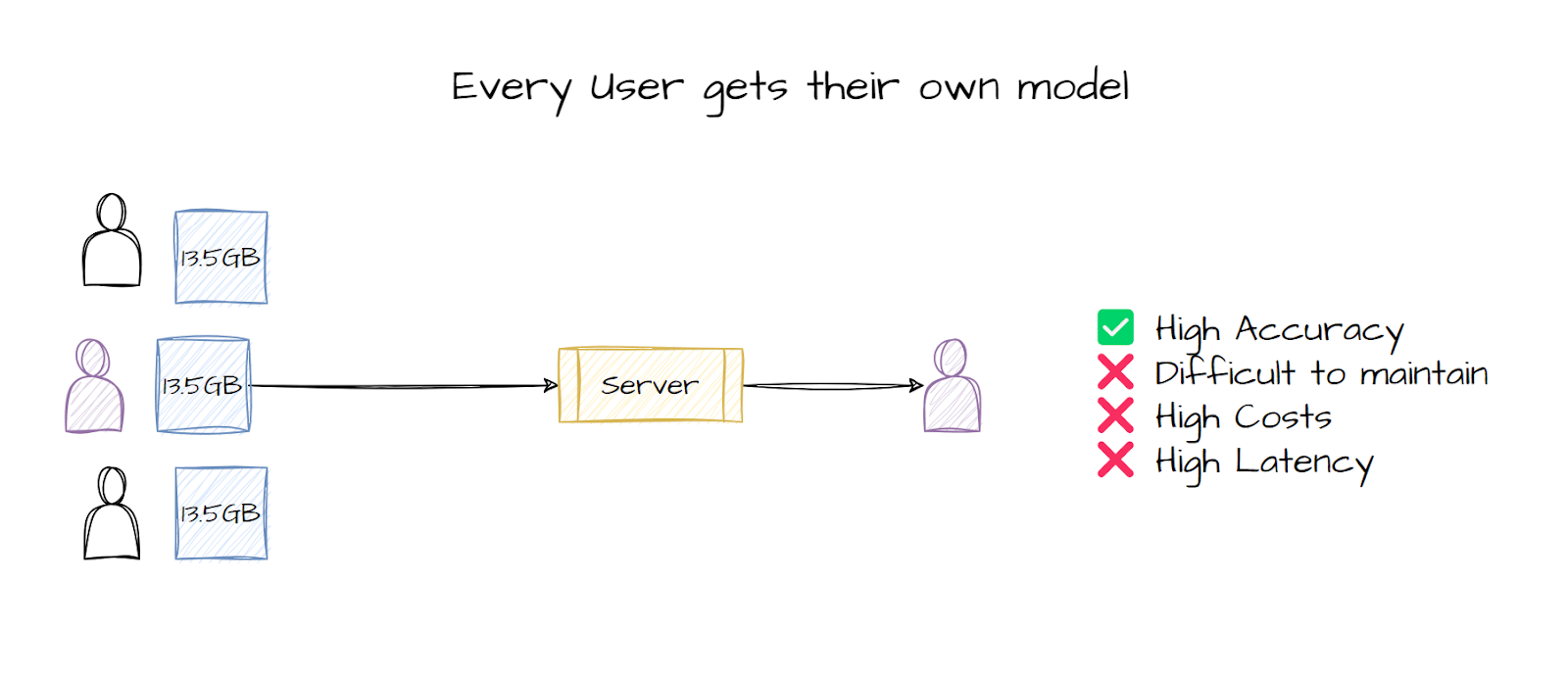
GPT-4 гэх мэт хэлний загварууд нь NLP салбарт бүтээгдэхүүн, хэрэглээг бий болгоход де-факто стандарт болсон. Эдгээр загварууд нь маш олон ажлыг гүйцэтгэх чадвартай. Гэхдээ эдгээр загварууд нь сургалт хийх процесст маш их асуудалтай гэж хэлж болно. GPT-4 гэх мэт асар том загваруудыг сургахад олон сая долларын зардал гардаг тул бид жижиг загваруудыг сургалтанд ашигладаг.
Нөгөө талаас жижиг загварууд нь олон даалгаврыг нэгтгэж чаддаггүй бөгөөд бид эцэст нь олон хэрэглэгчийн олон даалгаврын олон загвартай болдог. Эндээс л LoRA гэх мэт PEFT техникүүд орж ирдэг бөгөөд эдгээр техникүүд нь том загваруудыг бүрэн тохируулахаас хамаагүй илүү үр дүнтэй сургах боломжийг олгодог. Энэхүү нийтлэлд QLoRa болон LoRA-гийн тухай тайлбарлая
PEFT Finetuning гэж юу вэ?
PEFT Finetuing нь Параметрийн үр ашигтай нарийн тааруулах арга бөгөөд энгийн сургалтаас хамаагүй илүү үр дүнтэй загваруудыг нарийн тааруулж, сургах боломжийг олгодог. PEFT арга нь ихэвчлэн мэдрэлийн сүлжээн дэх сургах боломжтой параметрүүдийн тоог багасгах замаар ажилладаг. Хамгийн алдартай бөгөөд ашиглагдаж буй PEFT арга бол Prefix Tuning, P-tuning, LoRA гэх мэт. LoRA бол хамгийн их ашиглагддаг арга юм. LoRA нь QLoRA, LongLoRA гэх мэт олон хувилбартай бөгөөд тэдгээр нь өөрийн гэсэн програмтай байдаг.
Яагаад PEFT Finetuning ашиглах хэрэгтэй вэ?
PEFT техникийг ашиглах олон шалтгаан байдаг бөгөөд тэдгээр нь LLM болон бусад загваруудыг Finetune хийх арга зам болсон. Гэхдээ аж ахуйн нэгжүүд болон томоохон бизнесүүд эдгээр аргыг ашиглах дуртай зарим шалтгааныг энд дурдъя.
Цаг хэмнэнэ
Сургах боломжтой параметрүүдийн тоо буурах тусам сургалтанд бага цаг зарцуулах шаардлагатай болдог. Гэхдээ энэ нь зөвхөн нэг хэсэг юм. Бага сургах боломжтой параметрүүдээр та загваруудыг илүү хурдан сургах боломжтой бөгөөд үүний үр дүнд загваруудыг илүү хурдан турших боломжтой. Өөрийнхөө гарт илүү их цаг зарцуулснаар та янз бүрийн загвар, өөр өөр өгөгдлийн багц, өөр өөр арга техникийг туршиж үзэхэд зарцуулж болно.
Түүнчлэн, илүү их цаг хугацаа өнгөрөх тусам та загваруудаа илүү урт хугацаанд сургах боломжтой бөгөөд энэ нь PEFT техникийг санах ойн хэрэглээнд ихээхэн оновчтой болгосон тул багцын хэмжээ нэмэгдэхийн зэрэгцээ алдагдлыг багасгахад хүргэдэг.
Мөнгө хэмнэнэ
Энэ нь ойлгомжтой боловч PEFT нь тооцооллын зардалд маш их мөнгө хэмнэж чадна. Өмнө дурьдсанчлан санах ойн оновчлол их байдаг тул та жижиг VRAM-д том багцуудыг багтаах боломжтой тул их хэмжээний VRAM түрээслэх шаардлагагүй. Энэ нь тооцоололд мөнгө хэмнэж, илүү том багцад тохирох давуу талыг ашиглан илүү том өгөгдлийн багц дээр сургах боломжийг танд олгоно.
Олон түрээсийн архитектурын үйлчилгээг хялбархан бүтээх
Өмнө дурьдсанчлан, LLM нь маш том бөгөөд үйлчлэх, зохицуулахад төвөгтэй болсон тул хэрэглэгчдэд зориулсан тусгай загваруудыг сургах бараг боломжгүй юм. Хэрэв та олон хэрэглэгчтэй бол шинэ хэрэглэгч орж ирэх бүрт шинэ загварыг нарийн тааруулах гэх мэт төвөгтэй ажлыг хийх эсвэл шинэ хэрэглэгчийн шинэ өгөгдөл дээр ижил загварыг нарийн тааруулж болно. Энэ хоёр арга хоёулаа өөр өөрийн гэсэн асуудлуудтай байдаг, хэрэв та хэрэглэгч бүрт шинэ загвар тохируулбал илүү нарийвчлалтай болох боловч дараа нь та асар том загваруудыг зохицуулах, санах ойд ачаалах, хадгалах, боловсруулах гэх мэтийг хийх хэрэгтэй, энэ бол архитектур юм. там, хэрэв та жижиг алдаа гаргавал том асуудал үүсгэж болно. Бүх хэрэглэгчдэд ижил загварыг сургах нь илүү хялбар боловч дараа нь загварын нарийвчлал мэдэгдэхүйц буурдаг.
LoRA
LoRA бол хамгийн алдартай, магадгүй хамгийн их ашиглагддаг PEFT арга боловч 2021 онд энэ нийтлэлд гарсан. LoRA нь илүү адаптерийн арга бөгөөд загварт эдгээр шинэ параметрүүдээр дамжуулан загварыг сургах шинэ параметрүүдийг нэвтрүүлдэг. Загварын нийт параметрийн тоог нэмэгдүүлэхгүйгээр шинэ параметрүүдийг хэрхэн нэвтрүүлж, загварт буцааж нэгтгэж байгаа нь заль мэх юм.
LoRA хэрхэн ажилладаг вэ?
Өмнө дурьдсанчлан, LoRA бол адаптер дээр суурилсан арга боловч шинэ параметрүүдийг зөвхөн сургалтын алхамд зориулж нэмсэн бөгөөд тэдгээрийг загварын нэг хэсэг болгон танилцуулаагүй болно. Энэ нь загварын хэмжээг бүрэн ижил байлгах бөгөөд параметрийн хэмнэлттэй нарийн тааруулах уян хатан байдлыг санал болгодог.
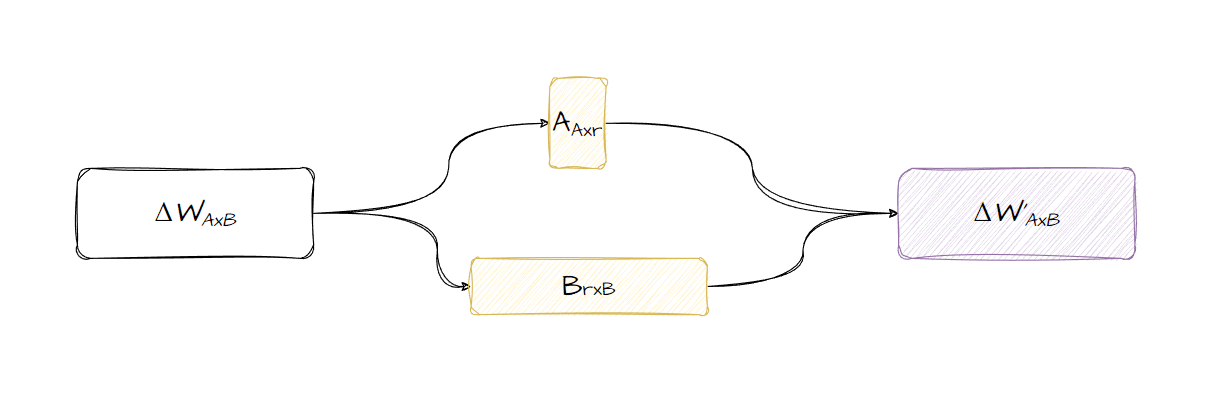
LoRA нь жинг шинэчлэх матрицыг жижиг матрицууд болгон задалж, загварыг сургахад ашигладаг. ΔWAxB нь жинг шинэчлэх матриц, буцаан тархалтаас олж авсан өөрчлөлтүүдийн матриц бөгөөд энэ нь бидний загварыг нарийн тааруулахын тулд шинэчлэх шаардлагатай параметрүүдийн тоотой ижил хэмжээтэй байна. Энэ матрицыг эсвэл дурын матрицыг r-ийг зэрэглэл болгон A ба B хэлбэрээр харуулсан жижиг матрицуудын багц хэлбэрээр илэрхийлж болно. r параметр нь жижиг матрицуудын хэмжээг хянадаг.
Дараа нь эдгээр жижиг матрицуудыг загварт шууд шинэчлэх бус харин жижиг матрицын параметрүүдийг шинэчлэхийн тулд ердийн ухрах тархалтыг ашиглан загварыг сургахад ашиглаж болно. Бид үндсэндээ ΔW-ийг жижиг матрицуудаар дамжуулан сурдаг. Дараа нь эдгээр жижиг матрицуудыг хооронд нь үржүүлж анхны матрицыг буцааж авах боломжтой. Эдгээр матрицууд нь хамаагүй бага байдаг тул энэ процесс нь цөөн тооны параметрүүдийг ашигладаг бөгөөд үүний үр дүнд тооцооллын нөөц бага байдаг. Энэ нь мөн загварыг бүхэлд нь хадгалах шаардлагагүй, харин зөвхөн жижиг матрицуудыг хадгалахад жижиг хяналтын цэгүүдийг бий болгодог.
QLoRA
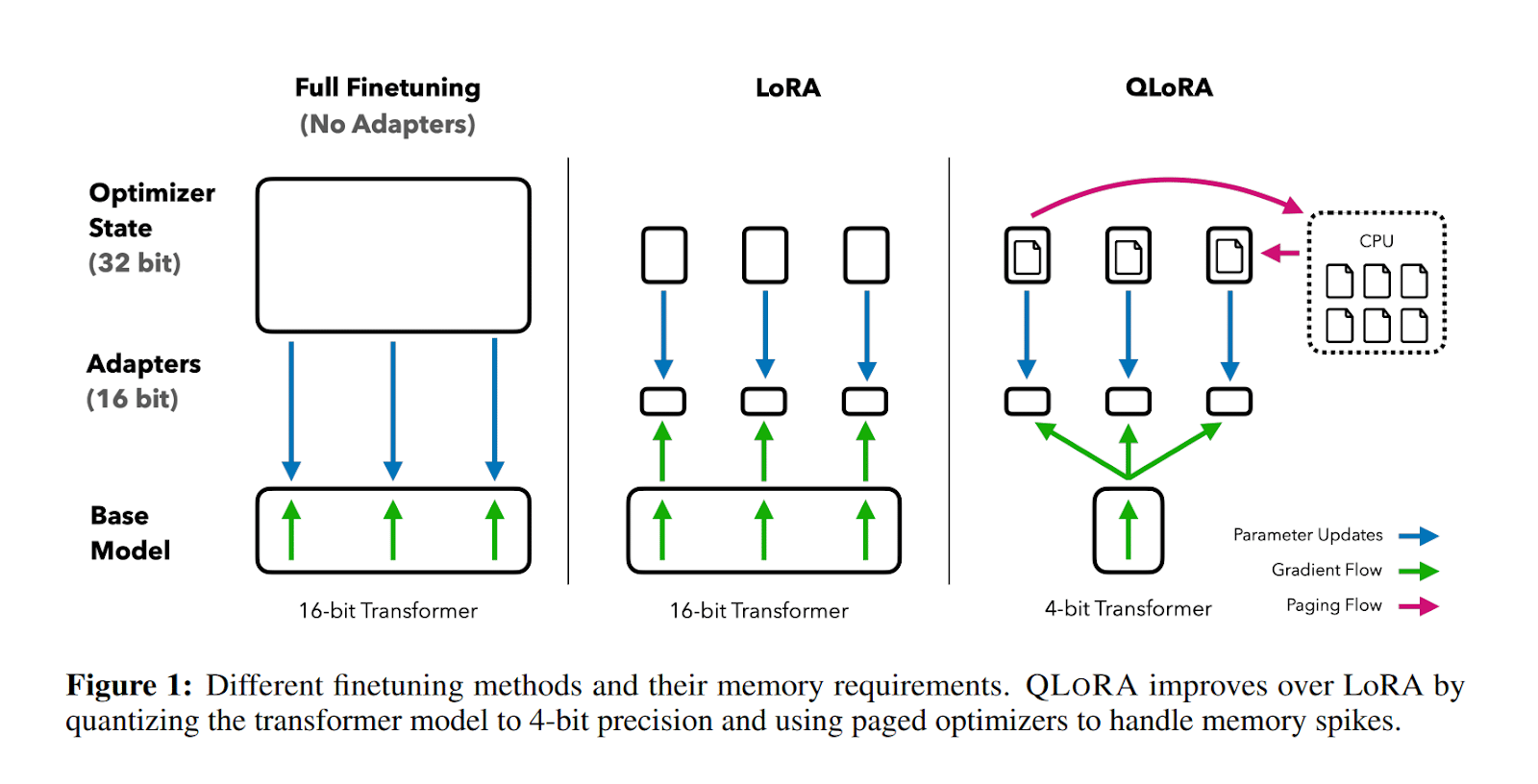
QLoRA нь ижил чанарын гүйцэтгэлийг хадгалахын зэрэгцээ санах ойг багасгахад туслах 3 шинэ үзэл баримтлалыг нэвтрүүлж ажилладаг. Эдгээр нь 4 битийн Normal Float, Double Quantization, Paged Optimizers юм.
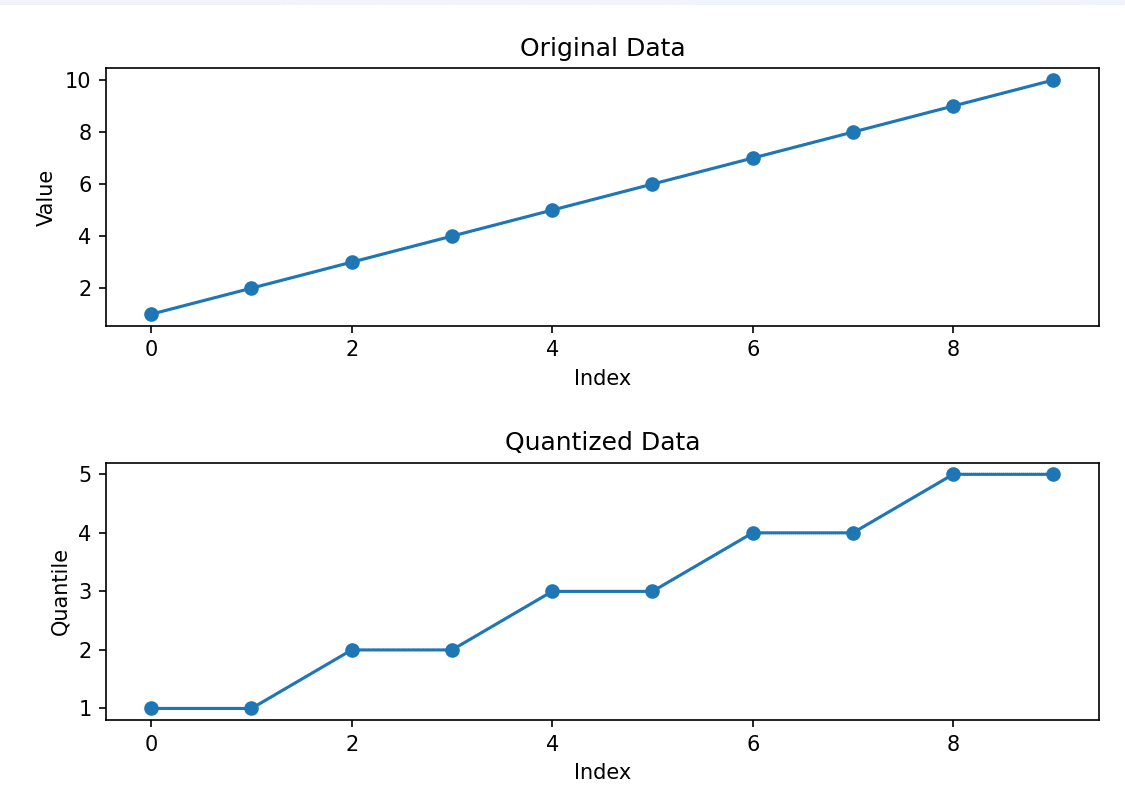
4-Bit Normal Float
4 битийн NormalFloat буюу NF нь Quantile Quantization техник дээр суурилсан онолын хувьд оновчтой мэдээллийн шинэ төрөл юм. 4-бит NF нь 0-ээс 1 хүртэлх тархалт дахь 2k + 1 (k нь битийн тоо) квантилуудыг тооцоолж, утгыг нь [-1, 1] мужид хэвийн болгох замаар ажилладаг. Үүнийг олж авсны дараа бид мэдрэлийн сүлжээний жинг [-1, 1] мужид хэвийн болгож, дараа нь 2-р алхамаас авсан квантилууд руу квантлах боломжтой. .
QLoRA болон Стандарт Finetune
Уг нийтлэлд судлаачид сүлжээний QLoRA, LoRA болон бүрэн нарийн тохируулгын хооронд маш нарийвчилсан харьцуулалтыг гаргажээ.
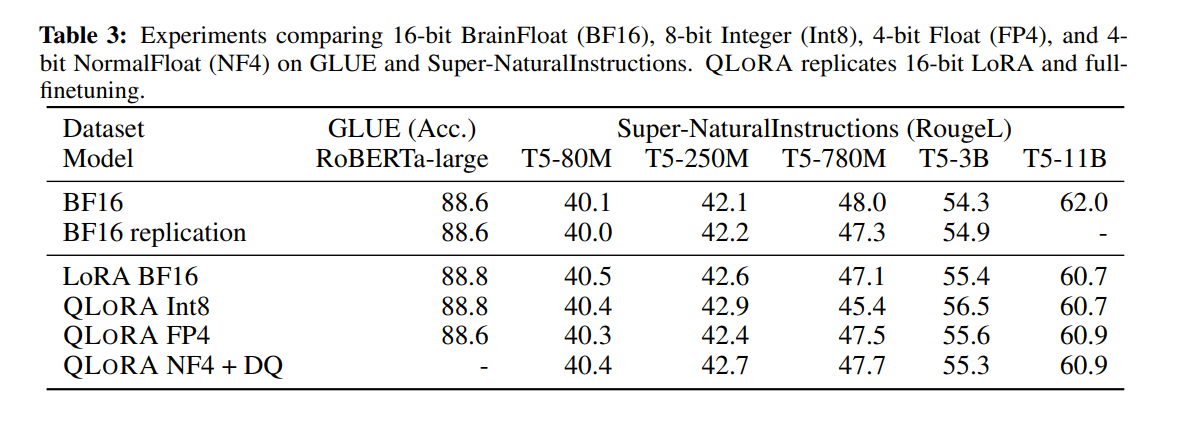
Дээрх хүснэгтээс харж байгаагаар T5 загварын QLoRA-д сургаж, тэр ч байтугай Давхар хэмжигдэхүүнтэй харьцуулахад гүйцэтгэлийн алдагдал байхгүй ч бид ямар ч томоохон ялгаа олж харахгүй байна. Нэг чухал ялгаа нь шаардлагатай LoRA адаптеруудын тоо юм. Уг нийтлэлд зохиогчид ердийн LoRA-ийн нарийн тохируулгатай харьцуулахад QLoRA-г нарийн тааруулахад илүү их LoRA адаптер хэрэгтэйг дурджээ. Зохиогчид LoRA адаптеруудыг бүх шугаман трансформаторын блокуудад асуулга, түлхүүр, утгын давхаргын хамт хэрэглэхийг санал болгож байна.
Илүү том хэлний загваруудын хувьд ч гүйцэтгэл нь ижил хэвээр байна:
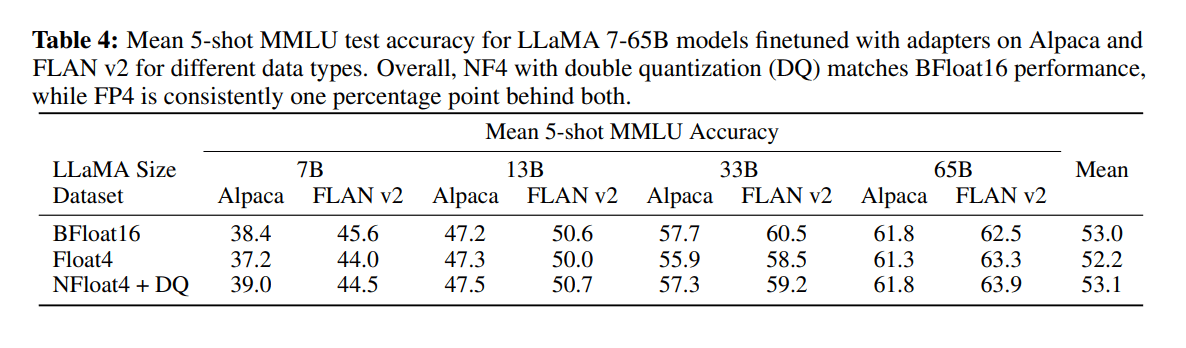
Тиймээс зохиолчид Гуанакогийн үндсэн LLaMA загварууд дээр model бэлтгэсэн. Энэ нь OASST1 өгөгдлийн багц дээр бэлтгэгдсэн 33 тэрбум параметрийн загвар юм. Гарсан үедээ энэ нь хамгийн сүүлийн үеийн загвар болж, ChatGPT-тэй харьцуулахад 99.3% гүйцэтгэлтэй болсон. Бусад загварууд нь Vicuna 13B, Guanaco33B зэрэг бага загвартай байсан ч 4 битийн нарийвчлалыг ашигласан тул 13B загвараас бага санах ой ашигладаг. .
Шинэ бичвэрүүд

How to Find and Fix Errors in Your Code 2025-01-19

Arithmetic Logic Unit (ALU) гэж юу 2025-01-18
