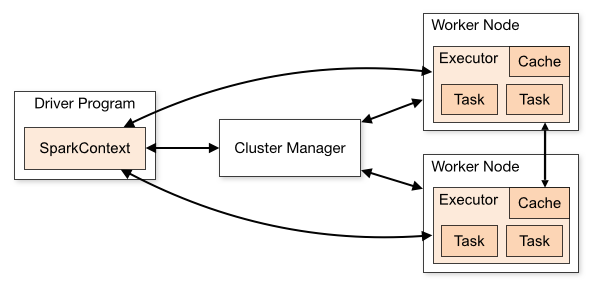
• Standalone – Spark-тай хамт ирдэг энгийн кластер менежер бөгөөд кластерыг хялбархан тохируулах боломжийг олгодог.
• Apache Mesos – Mesos нь кластер менежер бөгөөд Hadoop MapReduce болон Spark програмуудыг ажиллуулах боломжтой.
• Hadoop YARN – Hadoop 2-ын нөөцийн менежер бөгөөд ихэвчлэн ашиглагддаг кластер менежер юм.
• Kubernetes – Containerized програмуудыг автоматаар ажиллуулах, хуваарилах, удирдах боломжийг олгодог нээлттэй эхийн систем юм.
local – Энэ нь жинхэнэ кластер менежер биш ч гэсэн би “local” гэдэг үгийг master()-д ашиглах ёстой, ингэснээр компьютер дээр Spark-ийг ажиллуулах боломжтой болно.